Please see The HDF Group's new Support Portal for the latest information.
Figure a C Example
|
Figure b FORTRAN 90 Example |
|
|
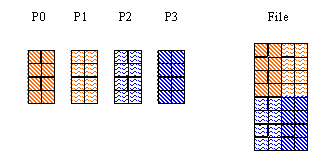
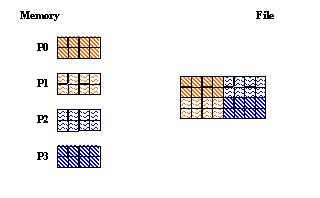
For this example, four processes are used, and a 4 x 2 chunk is written to the dataset by each process.
To do this, you would:
- Use the block parameter to specify a chunk of
size 4 x 2 (or 2 x 4 for Fortran 90).
- Use a different offset (start) for each process,
based on the chunk size:
C: Process 0 Process 1 Process 2 Process 3 --------- --------- --------- --------- offset[0] = 0 offset[0] = 0 offset[0] = 4 offset[0] = 4 offset[1] = 0 offset[1] = 2 offset[1] = 0 offset[1] = 2 FORTRAN 90: offset(1) = 0 offset(1) = 2 offset(1) = 0 offset(1) = 2 offset(2) = 0 offset(2) = 0 offset(2) = 4 offset(2) = 4
Figure a C Example
|
Figure b FORTRAN 90 Example |
|
|
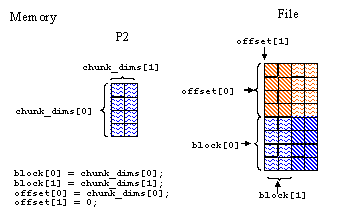
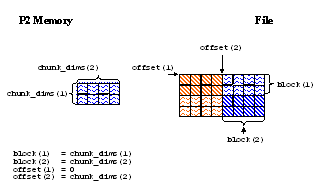
Below is an example program for writing hyperslabs by chunk in Parallel HDF5:
-
[ C Example ]
--
Hyperslab_by_chunk.c[ F90 Example ] --
hyperslab_by_chunk.f90
HDF5 "SDS_chnk.h5" {
GROUP "/" {
DATASET "IntArray" {
DATATYPE H5T_STD_I32BE
DATASPACE SIMPLE { ( 8, 4 ) / ( 8, 4 ) }
DATA {
1, 1, 2, 2,
1, 1, 2, 2,
1, 1, 2, 2,
1, 1, 2, 2,
3, 3, 4, 4,
3, 3, 4, 4,
3, 3, 4, 4,
3, 3, 4, 4
}
}
}
}
The h5dump utility is a C program, and the output is in C order.
- - Last modified: 05 July 2016